19Dec/24Off
This is where the data to build AI comes from
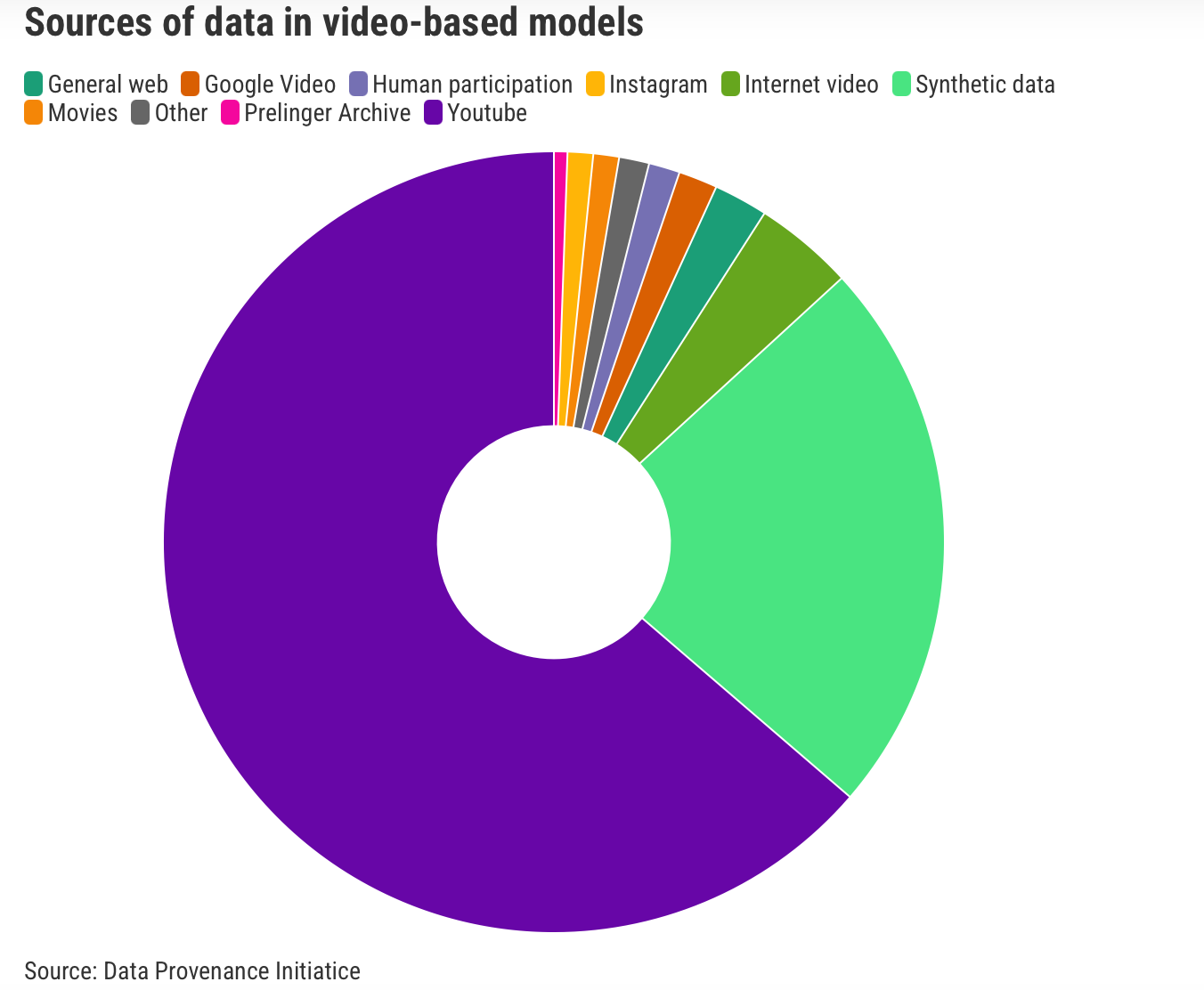
They audited nearly 4,000 public data sets spanning over 600 languages, 67 countries, and three decades. The data came from 800 unique sources and nearly 700 organizations. ...
Today, most AI data sets are built by indiscriminately hoovering material from the internet. Since 2018, the web has been the dominant source for data sets used in all media, such as audio, images, and video, and a gap between scraped data and more curated data sets has emerged and widened. ...
See the full story here: https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/